selbekk

Is Redux Dead?
Is Redux still worth learning in 2021? This article dives into where it came from, and what you can use instead.
React revolutionized front end development as most people knew it when it was first released. This new approach to writing code triggered incredible innovation in how to handle state changes and UI updates.
This revolution had its downsides, too. One of them was a culture of over-engineering solutions to challenges that could be solved in simpler ways. A typical example of this is how state has been managed in React applications.
Redux has become a hallmark of many React applications created in the last couple of years. The allure of having a single state object, available everywhere in your application sure sounds nice. But has its time passed? Has React evolved to a point where these kinds of state management tools add more complexity than they solve?
This article aims to give you a deeper understanding of which situations warrants state management tools like Redux. We’ll discuss the reasons behind the rise of Redux, and what has changed in the last couple of years - both in React and in Redux. Finally, we’ll look into what might be coming in the future.
Redux - and why people started using it
When it was first released , React didn’t have an officially supported way to pass data far down the component tree. If you had some kind of shared state, configuration or other information you would like to use anywhere in you application, you had to pass it down from parent to child to sibling to another child. There was a way to avoid it, but that way - the “legacy context API” was never officially supported, and was documented with a warning that it should not be used.
About the same time React was released to the public, some other Facebook engineers introduced a blueprint for how they created front end applications - the Flux architecture. It complimented React’s component-centric design by having a unidirectional data flow, which made things both easy to follow and simple to understand.
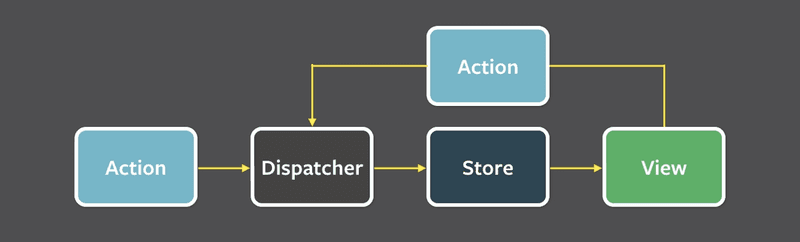
(photo borrowed from https://facebook.github.io/flux/docs/in-depth-overview)
While many famous open sourcerers were busy fighting over which slightly different implementation of this was the best, a young Russian developer named Dan Abramov introduced an implementation based on the Elm architecture, called Redux.
Redux was a pretty simple system, with a single state object, encased in a “store”, which could be updated by dispatching actions on it. The actions were sent to a “reducer” function, which returned a brand new copy of the entire application state, which would then propagate across your application.
Another great feature of Redux was how easy it was to use with React. Not only was it a great match with the programming model of React, it also solved the prop drilling issue! Just “connect” whatever component you want to a store, and you had access to any part of the application state you wanted. It was like magic!
Context, hooks, and why it solved much of what Redux did
With all its elegance and popularity though, Redux did have a few major downsides. For each new way of changing the state, you had to add a new action type and action creator, probably a dispatcher and a selector, and then you’d have to handle that new state change in an existing reducer, or create a new one. In other words - lots and lots of boilerplate.
When the 16.3 version of React was released, it finally shipped with a fully redesigned context API. With this new feature, prop drilling was suddenly as easy as wrapping any subsection of your application in a context provider, and fetching it again with a context consumer component. Here’s an example of how that could be done:
const UserContext = React.createContext();
class MyApp extends React.Component {
state = { user: null };
componentDidMount() {
myApi.getUser()
.then(user => this.setState({ user }));
}
render() {
return (
<UserContext.Provider value={this.state.user}>
<SomeDeepHierarchy />
</UserContext.Provider>
);
}
};
const UserGreeting = () => {
return (
<UserContext.Consumer>
{user => ( // look - no Redux required!
<p>Hello there, {user.name || 'customer'}!</p>
)}
</UserContext.Consumer>
);
};At ReactConf in 2018, now React Core team member Dan Abramov and boss Sophie Alpert introduced a new feature in React - hooks. Hooks made using state and side effects much easier, and made away with the need for class components altogether. In addition, the context API was suddenly much easier to consume, which made it much more user friendly. Here’s the revised code example with hooks:
const UserContext = React.createContext();
const useUser = () => {
const [user, setUser] = React.useState(null);
React.useEffect(() => {
myApi.getUser().then((user) => setUser(user));
}, []);
}
const MyApp = () => {
const user = useUser();
return (
<UserContext.Provider value={user}>
<SomeDeepHierarchy />
</UserContext.Provider>
);
};
const UserGreeting = () => {
const user = React.useContext(UserContext);
return <p>Hello there, {user?.name ?? "customer"}!</p>;
};With these new features landing in React, the trade-offs for using Redux changed quite a bit. The elegance of reducers were suddenly built into React itself, and prop-drilling was a solved challenge. New projects were started without having Redux in the stack - a previous no-brainer - and more and more projects started to consider moving away from Redux altogether.
Redux Toolkit and hooks - a new and improved user experience?
As a response, the team currently maintaining Redux (led by a gentleman named Mark Eriksson) started two different efforts. They introduced an opinionated toolkit named Redux Toolkit that did away with most boilerplate code through conventions, and they added a hooks-based API for reading state and dispatching actions.
Together these two new updates simplified Redux codebases substantially. But is it really enough to defend introducing the added complexity of the concepts in Redux to a new project? Is the value Redux adds more than the added cost of teaching new employees about Yet Another Tool?
Let’s look at where React does a great job by itself, and in what cases the tradeoff of complexity vs power is worth it.
When React is enough
Most React applications I’ve worked with have been pretty small in scope. They’ve had a few global pieces of state that was used across the application, and some data that was shared across a few different views.
Besides from this though, many React applications don’t have a lot of shared state. Most state like the content of input fields or whether a modal is open, is only interesting to the component that contains them! No need to make that state globally available.
Other pieces of state might be shared, but only by a part of the application. Perhaps a particular page requires a piece of state to be shared across several of its components, or a sidebar needs to expose some remote status to all of its children. Either way, that’s not global state - it’s state scoped to a part of the application.
By keeping state co-located, or as close to its dependents as possible, you ensure that it’s deleted whenever the feature requiring it is deleted, and that it’s discoverable without leafing through tens of different reducers.
If you need to share app-wide settings that rarely change, React’s context API is a great tool to reach for. One example of this is what locale is currently active:
const LocaleContext = React.createContext({
locale: "en-US",
setLocale: () => {},
});
const LocaleProvider = (props) => {
const [locale, setLocale] = React.useState("en-US");
return <LocaleContext.Provider value={{ locale, setLocale }} {...props} />;
};
const useLocale = () => React.useContext(LocaleContext);Other use cases can be what color theme is active, or even what experiments are active for a given user.
Another very useful approach is using a small data-fetching library like SWR or React-Query to handle fetching and caching your API responses for you. To me, cached data isn’t really global state - it’s just cached data. This is much simpler to handle with these small single-use libraries, than introducing async thunks or sagas to your Redux rig. Also, you don’t have to handle all the complex variations of isLoading, hasError and what not. With these libraries, it works out of the box.
A thing these context use cases have in common is the fact that they represent data that rarely updates. Rarely in the context of computer science is a bit vague, but in my mind, less than a couple of times every second is pretty rare. And as it turns out, that’s the way the React Context API works best!
The use cases summarized above covers most of the situations I’ve met in real world applications. Actual global state is rare and far between, and is often better off being co-located with the code that actually uses it, or provided through the context API.
Situations where Redux might be warranted
With all that said, Redux is still a great product. It’s well documented, adopted by many, and can be combined with the approaches posted above. But what use cases warrants the added complexity and learning curve of adding Redux to your stack in 2021?
One of the use cases I see most in the projects I’m involved with is when you have advanced data fetching scenarios that requires a lot of cascading network communication. One might argue that this is best done on the server side, but there are definitely use cases where handing this on the client is warranted. Redux, particularly in combination with so-called thunks, is extremely versatile and flexible when it comes to such orchestration.
Another use case is for very interdependent states, or states that are derived from several other states. This is possible to handle in React as well, but the end result is still much easier to both share, reuse and reason about in Redux.
A third use case is for those where the state of your application can change very rapidly. The lead architect of React, Seb Markbåge, stated a few years ago that the current implementation of the context API was suboptimal for sharing data that updated quickly, since a change in the context-provided value would trigger a re-render of the entire subtree of components. Web socket driven trading or analytics dashboards might be good examples of such a situation. Redux gets around this by only sharing the store instance through context, and triggers re-renders more explicitly.
A final use case is highly subjective, and is for teams that enjoy the top-down single-state-tree approach. That the entire state of the application can be serialized, de-serialized, sent over the wire and persisted in local storage. That you can time-travel across changes, and provide a full story of actions leading to a bug to a bug tracking tool. These are powerful arguments, and definitely a value-add for some.
The other options
In my opinion, most applications can do without external state management libraries. Some disagree, and some have such advanced use cases that handling it without some kind of intermediary layer is very unpractical. In such cases, I suggest you look into Redux’ competition, before landing on the tried and true alternative.
MobX is a well-tested and popular state management tool that works through the magic of observables. It’s quick as heck, and most people that try it become fans within weeks. I haven’t tried it myself, so I won’t be advocating for it too strongly, but the design looks solid! Another contender is Recoil. This library also stems from the engineers at Facebook, and is based around the concept of atoms of state, and derived state called selectors. It’s very similar to React in its API design, and works flawlessly with it. It’s currently in an open beta, but it should still be useful in many projects.
The final alternative I want to suggest is Overmind. Overmind is the state library that runs the main editor application over at CodeSandbox, and is based around a single state tree and side effects. It’s also something I’ve never tried before, but by looking at the complexity and lack of bugs in CodeSandbox, it must be pretty powerful!
Even with all of these alternatives present, Redux is still holding its ground. With the recently added hooks and Redux Toolkit, the developer experience has really improved as well.
Summary
React is an incredible framework for creating quick, responsive and optimized user interfaces. It provides a flexible API for handling both simple and complex states, and the latest versions have improved the developer experience in such ways that most state management libraries really aren’t needed anymore.
There are definitely use cases where a separate state management layer is a net positive, and you should always consider introducing one when it’s needed. My argument is that you shouldn’t start out with one before you feel the pain of not having one. Only then can you be sure you’re not adding complexity to your stack without reaping any of the benefits.
All rights reserved © 2025